

关于机型选择
选择实例类型
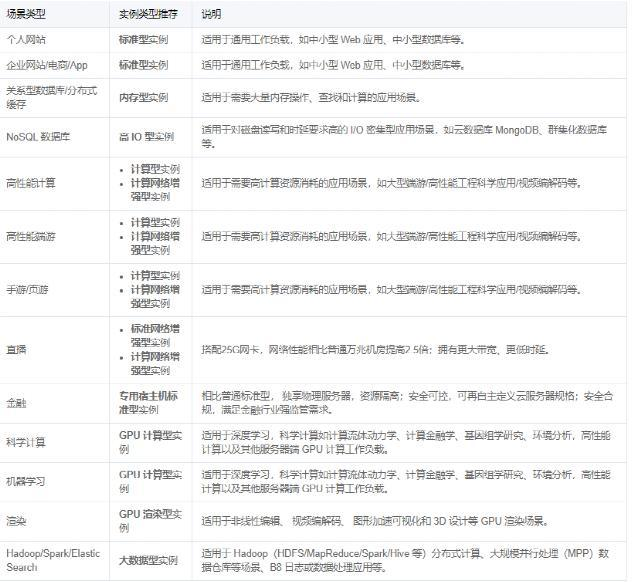
选择存储介质

最佳实践-如何衡量云硬盘的性能
dd简单测试云盘性能
(务必新购机器测试,切记不可线上业务测试。。。。)
(务必新购机器测试,切记不可线上业务测试 。。。。。)
(务必新购机器测试,切记不可线上业务测试,重要的事情说三次。。。。。)
新购的话记得提前领取优惠劵哦
建议递归测试,注意测试大小不能超过挂载点磁盘空间
#dd if=/dev/zero of=rdisk.img bs=1K count=200000 conv=fdatasync
#dd if=/dev/zero of=rdisk.img bs=1K count=2000000 conv=fdatasync

#iostat -x 10 观察IO变化
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈
rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rmerge)/s
wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
r/s: 每秒完成的读 I/O 设备次数。即 delta(rio)/s
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
rsec/s: 每秒读扇区数。即 delta(rsect)/s
wsec/s: 每秒写扇区数。即 delta(wsect)/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。(需要计算)
wkB/s: 每秒写K字节数。是 wsect/s 的一半。(需要计算)
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
avgqu-sz: 平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
fio深度测试云盘性能
(务必新购机器测试,切记不可线上业务测试。。。。)
(务必新购机器测试,切记不可线上业务测试 。。。。。)
(务必新购机器测试,切记不可线上业务测试,重要的事情说三次。。。。。)
点击领取腾讯云优惠劵
衡量指标
腾讯云提供的块存储设备根据类型的不同拥有不同的性能和价格,详细信息请参考 云硬盘类型。由于不同应用程序的工作负载不同,若未提供足够的 I/O 请求来充分利用云硬盘时,可能无法达到云硬盘的最大性能。
一般使用以下指标衡量云硬盘的性能:
lIOPS:每秒读/写次数,单位为次(计数)。存储设备的底层驱动类型决定了不同的 IOPS。
l吞吐量:每秒的读写数据量,单位为MB/s。
l时延:I/O 操作的发送时间到接收确认所经过的时间,单位为秒。
测试工具
FIO 是测试磁盘性能的工具,用来对硬件进行压力测试和验证,本文以 FIO 为例。
使用 FIO 时,建议配合使用 libaio 的 I/O 引擎进行测试。请您自行安装 FIO 和 libaio。
警告:
请不要在系统盘上进行 FIO 测试,避免损坏系统重要文件。
为避免底层文件系统元数据损坏导致数据损坏,请不要在业务数据盘上进行测试。
请确保
/etc/fstab
文件配置项中没有被测硬盘的挂载配置,否则将导致云服务器启动失败。
测试对象建议
l建议在空闲的、未保存重要数据的硬盘上进行 FIO 测试,并在测试完后重新制作被测硬盘的文件系统。
l测试硬盘性能时,建议直接测试裸数据盘(如 /dev/vdb)。
l测试文件系统性能时,推荐指定具体文件测试(如 /data/file)。
测试示例
不同场景的测试公式基本一致,只有 rw、iodepth 和 bs(block size)三个参数的区别。例如,每个工作负载适合最佳 iodepth 不同,取决于您的特定应用程序对于 IOPS 和延迟的敏感程度。
参数说明:
| 参数名 | 说明 | 取值样例 |
|---|---|---|
| bs | 每次请求的块大小。取值包括4k、8k及16k等。 | 4k |
| ioengine | I/O 引擎。推荐使用 Linux 的异步 I/O 引擎。 | libaio |
| iodepth | 请求的 I/O 队列深度。 | 1 |
| direct | l指定 direct 模式。True(1)表示指定 O_DIRECT 标识符,忽略 I/O 缓存,数据直写。 lFalse(0)表示不指定 O_DIRECT 标识符。 默认为 True(1)。 |
1 |
| rw | 读写模式。取值包括顺序读(read)、顺序写(write)、随机读(randread)、随机写(randwrite)、混合随机读写(randrw)和混合顺序读写(rw,readwrite)。 | read |
| time_based | 指定采用时间模式。无需设置该参数值,只要 FIO 基于时间来运行。 | N/A |
| runtime | 指定测试时长,即 FIO 运行时长。 | 600 |
| refill_buffers | FIO 将在每次提交时重新填充 I/O 缓冲区。默认设置是仅在初始时填充并重用该数据。 | N/A |
| norandommap | 在进行随机 I/O 时,FIO 将覆盖文件的每个块。若给出此参数,则将选择新的偏移量而不查看 I/O 历史记录。 | N/A |
| randrepeat | 随机序列是否可重复,True(1)表示随机序列可重复,False(0)表示随机序列不可重复。默认为 True(1)。 | 0 |
| group_reporting | 多个 job 并发时,打印整个 group 的统计值。 | N/A |
| name | job 的名称。 | fio-read |
| size | I/O 测试的寻址空间。 | 100GB |
| lfilename | 测试对象,即待测试的磁盘设备名称。 | /dev/sdb |
常见用例如下:
bs = 4k iodepth = 1:随机读/写测试,能反映硬盘的时延性能
执行以下命令,测试硬盘的随机读时延。
fio -bs=4k -ioengine=libaio -iodepth=1 -direct=1 -rw=randread -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randread-lat –size=10G -filename=/dev/vdb1
执行以下命令,测试硬盘的随机写时延。
fio -bs=4k -ioengine=libaio -iodepth=1 -direct=1 -rw=randwrite -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randwrite-lat –size=10G -filename=/dev/vdb1
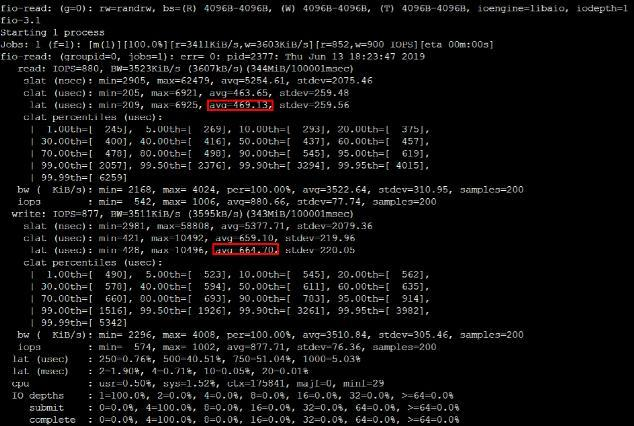
l执行以下命令,测试 SSD 云硬盘的随机混合读写时延性能。
fio –bs=4k –ioengine=libaio –iodepth=1 –direct=1 –rw=randrw –time_based –runtime=100 –refill_buffers –norandommap –randrepeat=0 –group_reporting –name=fio-read –size=1G –filename=/dev/vdb1
测试结果如下图所示:
bs = 128k iodepth = 32:顺序读/写测试,能反映硬盘的吞吐性能
执行以下命令,测试硬盘的顺序读吞吐带宽。
fio -bs=128k -ioengine=libaio -iodepth=32 -direct=1 -rw=read -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-read-throughput –size=10G -filename=/dev/vdb1
执行以下命令,测试硬盘的顺序写吞吐带宽。
fio -bs=128k -ioengine=libaio -iodepth=32 -direct=1 -rw=write -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-write-throughput –size=10G -filename=/dev/vdb1
执行以下命令,测试 SSD 云硬盘的顺序读吞吐性能。
fio –bs=128k –ioengine=libaio –iodepth=32 –direct=1 –rw=read –time_based –runtime=100 –refill_buffers –norandommap –randrepeat=0 –group_reporting –name=fio-rw –size=1G –filename=/dev/vdb1
测试结果如下图所示:

bs = 4k iodepth = 32:随机读/写测试,能反映硬盘的 IOPS 性能
执行以下命令,测试硬盘的随机读 IOPS。
fio -bs=4k -ioengine=libaio -iodepth=32 -direct=1 -rw=randread -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randread-iops –size=10G -filename=/dev/vdb1
执行以下命令,测试硬盘的随机写 IOPS。
fio -bs=4k -ioengine=libaio -iodepth=32 -direct=1 -rw=randwrite -time_based -runtime=600 -refill_buffers -norandommap -randrepeat=0 -group_reporting -name=fio-randwrite-iops –size=10G -filename=/dev/vdb1
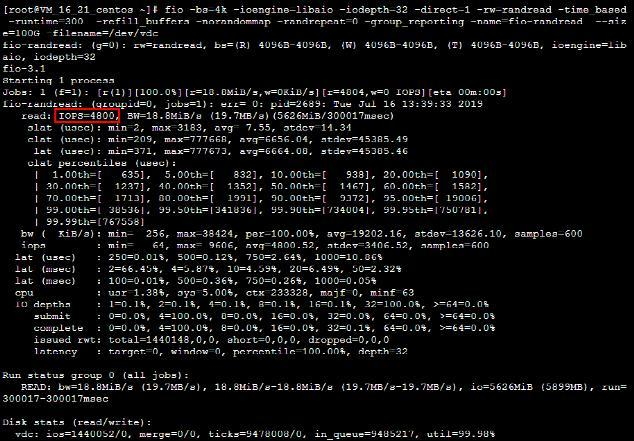
测试 SSD 云硬盘的随机读 IOPS 性能。如下图所示:
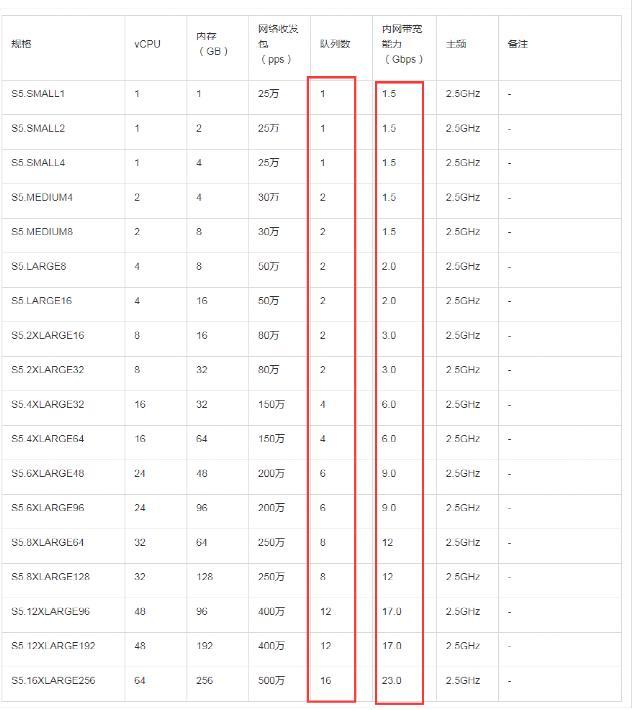
关于网络选择
内网带宽能力
公网带宽能力
| 网络计费模式 | 实例 | 带宽上限的可设置范围(Mbps) | |
|---|---|---|---|
| 实例计费模式 | 实例配置 | ||
| 按流量计费 | 按量计费实例 | ALL | 0 – 100 |
| 包年包月实例 | 核数 ≤ 8核 | 0 – 200 | |
| 8核 < 核数 <24核 | 0 – 400 | ||
| 核数 ≥ 24核 | 0 – 400或不限速 | ||
| 按带宽计费 | 按量计费实例 | ALL | 0 – 100 |
| 包年包月实例 | ¡广州一区 ¡广州二区 ¡上海一区 ¡香港一区 多伦多一区 |
0 – 200 | |
| 其他可用区 | 0 – 1000 | ||
| 共享带宽 | ALL | 0 – 1000或不限速 | |
公网带宽上限 内网性能测试
客户最佳实践
方案1 包年包月
优惠:点击领取优惠劵
适用:流量均衡,峰谷相差不大,门户网站,电商
条件:带宽利用率大于10%,即每天的峰值流量>=2.4小时
特性:按月预付费

方案2 按流量计费
优惠:点击领取优惠劵
适用:流量不均衡,峰谷相差巨大,大数据,CDN源站等场景
条件:带宽利用率低于10%,即每天的峰值流量<=2.4小时
特性:按小时结算公网出流量

方案3 共享带宽包
优惠:点击领取优惠劵
适用:流量均衡,峰谷相差不大,小程序,游戏
条件:带宽利用率大于10%,,即每天的峰值流量>=2.4小时
特性:按月后付费
常见丢包问题
案例1 网卡接受队列溢出丢包问题处理
irqbalance考虑三个因素
lcpu中断的负载(包括软中断和硬中断),选择一个负载最低的
l中断所属设备的类型(网卡,磁盘,还是其他设备),不同类型的设备,绑定的策略不一样,比如网卡会固定绑定到一个超线程上,磁盘中断绑定在一个core上。其他类型中断绑定到所有cpu上。
l设备推荐的cpu,比如numa架构,某些设备可能属于某一个numa,这样对应的中断发送到所属的numa性能会更好。
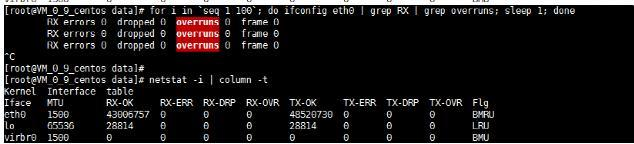
1、机器CPU负载低,但通过 ifconfig 看到 overruns 字段在不停的增大
for i in seq 1 100; do ifconfig eth0 | grep RX | grep overruns; sleep 1; done
这里一直增加
RX packets:26191785302 errors:0 dropped:0 overruns:45732243 frame:0
# netstat -i | column -t
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 0 26191244868 0 0 45732243 20141056331 0 0 0 BMRU
lo 16436 0 4937053994 0 0 0 4937053994 0 0 0 LRU
原因:接受队列溢出产生错误,当抵达的包多于内核可以处理的包时,计算机会产生漫溢(overruns)。输入队列达到其上限(max_backlog)时,多抵达的那些包会全部被丢弃掉。
RX errors: 表示总的收包的错误数量,这包括 too-long-frames 错误,Ring Buffer 溢出错误,crc 校验错误,帧同步错误,fifo overruns 以及 missed pkg 等等。
RX dropped: 表示数据包已经进入了 Ring Buffer,但是由于内存不够等系统原因,导致在拷贝到内存的过程中被丢弃。
RX overruns: 表示了 fifo 的 overruns,这是由于 Ring Buffer(aka Driver Queue) 传输的 IO 大于 kernel 能够处理的 IO 导致的,而 Ring Buffer 则是指在发起 IRQ 请求之前的那块 buffer。很明显,overruns 的增大意味着数据包没到 Ring Buffer 就被网卡物理层给丢弃了,而 CPU 无法即时的处理中断是造成 Ring Buffer 满的原因之一,上面那台有问题的机器就是因为 interruprs 分布的不均匀(都压在 core0),没有做 affinity 而造成的丢包。
2、问题优化和解决
1.关闭irqbalance(默认的是最优的)
systemctl stop irqbalance
systemctl status irqbalance
2.执行镜像内绑核优化脚本
/usr/local/qcloud/irq/net_smp_affinity.sh >/tmp/net_affinity.log 2>&1
- 把磁盘中断绑定到一个核上
echo 1 > /proc/irq/25/smp_affinity
echo 1 > /proc/irq/27/smp_affinity
再次执行脚本看overruns不在增加
for i in seq 1 100; do ifconfig eth0 | grep RX | grep overruns; sleep 1; done
4.如优化后问题依然不能解决,可以考虑升级CPU配置提升性能
FAQ 绑核的由来
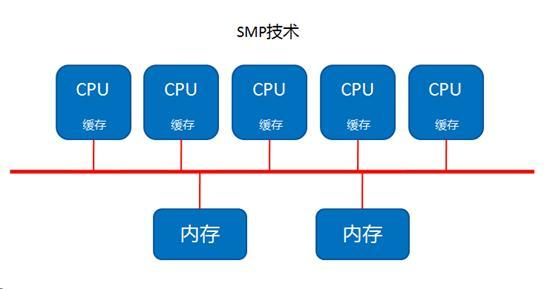
SMP(Symmetric Multi-Processor) :对称多处理器
SMP 服务器的主要特征是共享,系统中所有资源 (CPU 、内存、 I/O 等 ) 都是共享的。也正是由于这种特征,导致了 SMP 服务器的主要问题,那就是它的扩展能力非常有限。对于 SMP 服务器而言,
每一个共享的环节都可能造成 SMP 服务器扩展时的瓶颈,而最受限制的则是内存。由于每个 CPU 必须通过相同的内存总线访问相同的内存资源,因此随着 CPU 数量的增加,内存访问冲突将迅速增加,
最终会造成 CPU 资源的浪费,使 CPU 性能的有效性大大降低, SMP 服务器 CPU 利用率最好的情况是 2 至 4 个 CPU 。
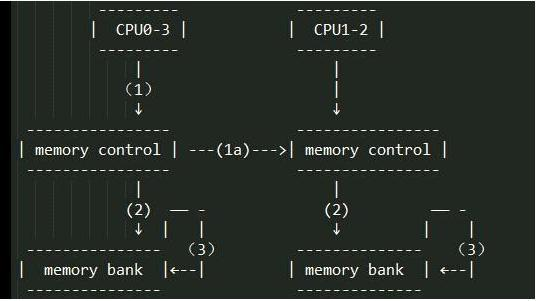
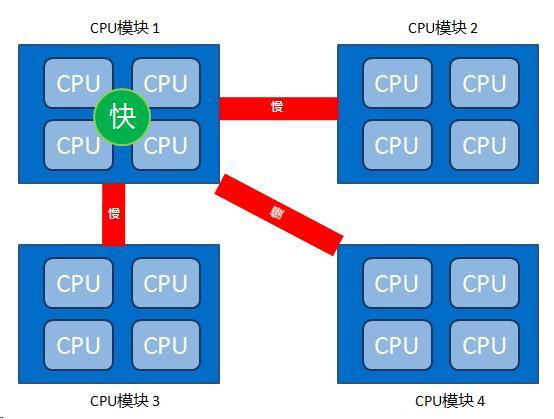
NUMA(Non-Uniform Memory Access):非一致性内存访问
NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互,这就是通常说的绑核的来源
在NUMA中还有三个节点的概念:
l本地节点: 对于某个节点中的所有CPU,此节点称为本地节点。
l邻居节点:与本地节点相邻的节点称为邻居节点。
l远端节点:非本地节点或邻居节点的节点,称为远端节点。
numactl –hardware
available: 1 nodes (0)
node 0 cpus: 0 1
node 0 size: 4095 MB
node 0 free: 323 MB
node distances:
node 0
0: 10
案例2 nf_conntrack: table full, dropping packet 问题解决
nf_conntrack 工作在 3 层,支持 IPv4 和 IPv6,而 ip_conntrack 只支持 IPv4。目前,大多的 ip_conntrack_* 已被 nf_conntrack_* 取代,很多 ip_conntrack_* 仅仅是个 alias,原先的 ip_conntrack 的 /proc/sys/net/ipv4/netfilter/ 依然存在,但是新的
nf_conntrack 在 /proc/sys/net/netfilter/ 中,这个应该是做个向下的兼容: (suse在/proc/net/nf_conntrack)
查看当前的连接数:
$ grep nf_conntrack /proc/slabinfo
nf_conntrack_expect 0 0 240 16 1 : tunables 120 60 8 : slabdata 0 0 0
nf_conntrack_ffffffff80745300 800044 841692 312 12 1 : tunables 54 27 8 : slabdata 70141 70141 54
查出目前 nf_conntrack 的排名:
$ cat /proc/net/nf_conntrack | cut -d ‘ ‘ -f 10 | cut -d ‘=’ -f 2 | sort | uniq -c | sort -nr | head -n 10
nf_conntrack/ip_conntrack 跟 nat 有关,用来跟踪连接条目,它会使用一个哈希表来记录 established 的记录。nf_conntrack 在 2.6.15 被引入,而 ip_conntrack 在 2.6.22 被移除,如果该哈希表满了,就会出现:
nf_conntrack: table full, dropping packet
解决此问题思路
1.可以通过 echo 直接修改目前系统 CONNTRACK_MAX 以及 HASHSIZE 的值:
echo 3100000> /proc/sys/net/netfilter/nf_conntrack_max
2.编辑内核参数,执行sysctl -p生效
vi /etc/sysctl.conf
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432
net.ipv4.tcp_rmem =4096 65536 131072
net.ipv4.tcp_wmem =4096 65536 131072
net.ipv4.tcp_mem =6553600 6553600 6553600
net.core.netdev_max_backlog = 2500
vm.min_free_kbytes = 65536
vm.swappiness = 0
net.ipv4.ip_local_port_range = 1024 65535
fs.file-max = 9000000
fs.nr_open = 9000000
net.ipv4.tcp_fin_timeout=10
net.ipv4.tcp_keepalive_time = 2400
net.ipv4.tcp_window_scaling = 0
net.ipv4.tcp_sack = 0
net.ipv4.tcp_max_syn_backlog=8192
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_tw_recycle = 1
net.netfilter.nf_conntrack_max = 31000000
net.ipv4.tcp_max_orphans = 655350
kernel.suid_dumpable = 1
net.ipv4.route.max_size = 25000000
3.使用 raw 表,不跟踪连接
iptables 中的 raw 表跟包的跟踪有关,基本就是用来干一件事,通过 NOTRACK 给不需要被连接跟踪的包打标记,也就是说,如果一个连接遇到了 -j NOTRACK,conntrack 就不会跟踪该连接,raw 的优先级大于 mangle, nat, filter,
包含 PREROUTING 和 OUTPUT 链。
当执行 -t raw 时,系统会自动加载 iptable_raw 模块(需要该模块存在)。raw 在 2.4 以及 2.6 早期的内核中不存在,除非打了 patch,目前的系统应该都有支持:
iptables -A FORWARD -m state –state UNTRACKED -j ACCEPT
iptables -t raw -A PREROUTING -p tcp -m multiport –dport 443,5223,2012,1989 -j NOTRACK
iptables -t raw -A PREROUTING -p tcp -m multiport –sport 443,5223,2012,1989 -j NOTRACK
案例3 nginx 反向代理SYN连接问题处理
业务最近发现 nginx 反向代理服务器SYN 连接特别多
tail -f /var/log/messages
Dec 24 09:31:29 lf-weather-lvs-101-11 kernel: [7406388.265092] possible SYN flooding on port 8080. Sending cookies.
Dec 24 09:32:50 lf-weather-lvs-101-11 kernel: [7406469.537620] possible SYN flooding on port 8080. Sending cookies.
Dec 24 09:35:02 lf-weather-lvs-101-11 kernel: [7406600.783795] possible SYN flooding on port 8080. Sending cookies.
Dec 24 09:38:30 lf-weather-lvs-101-11 kernel: [7406809.145161] possible SYN flooding on port 8080. Sending cookies.
Dec 24 09:39:57 lf-weather-lvs-101-11 kernel: [7406895.519336] possible SYN flooding on port 8080. Sending cookies.
Dec 24 09:41:05 lf-weather-lvs-101-11 kernel: [7406964.278512] possible SYN flooding on port 8080. Sending cookies.
Dec 24 09:44:26 lf-weather-lvs-101-11 kernel: [7407164.819061] possible SYN flooding on port 8080. Sending cookies.
解决步骤
1.网络TCP UDP连接排名
netstat -ntu | awk ‘{print $5″\n”}’ | cut -d: -f1 | sort | uniq -c | sort -nr|head -n 10
54456
44 220.202.103.116
41 61.50.248.5
37 111.20.241.255
30 220.201.8.217
29 113.57.255.1
……..
2.连接状态排名
netstat -n | awk ‘/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’
TIME_WAIT 1293
CLOSE_WAIT 1
FIN_WAIT1 3428
ESTABLISHED 5330
FIN_WAIT2 46193
SYN_RECV 371
CLOSING 32
LAST_ACK 113
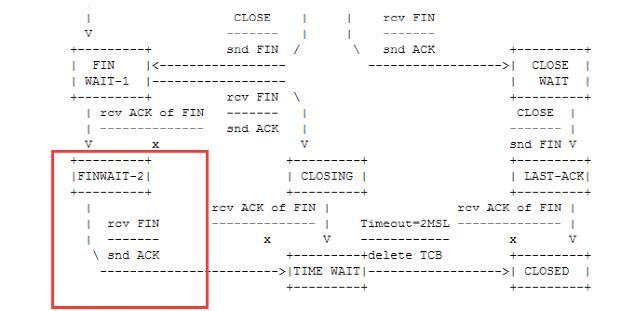
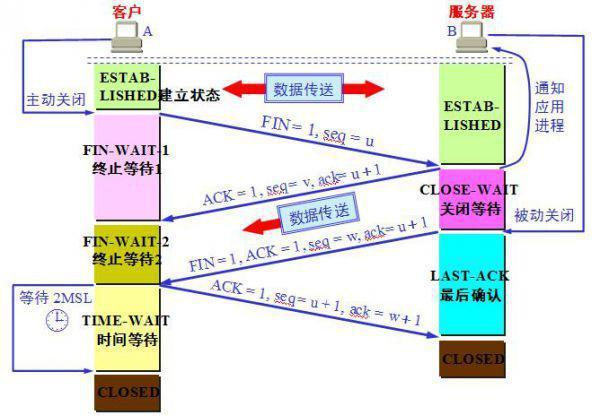
发现FIN_WAIT2特别多,它的转移条件只有一个,即收到对端的FIN,然后进入TIMEWAIT,如果对端故意不发送FIN,且也不传输数据,那么意味着本端始终处在FINWAIT-2状态而资源无法释放,这不正是一个DDoS的典型场景
3.nginx client IP 连接数排名
awk ‘{print $1}’ access__xx.log|awk ‘{count[$1]++}END{for(i in count)print i,count[i]}’|sort -n -k 2 -r |head -n 5
112.97.30.1 417
61.50.248.5 371
61.55.156.20 368
119.145.15.27 361
58.251.152.27 351
4.调整后的内核差数如下
vi /etc/sysctl.conf
net.ipv4.route.gc_timeout=30 #tcp连接超时时间 之前是60
net.ipv4.ip_local_port_range = 1024 65535 #tcp端口的使用范围
net.ipv4.tcp_tw_reuse = 1 #表示开启TCP连接中TIME-WAIT sockets的快速回收 新添加
net.ipv4.tcp_tw_recycle = 1 #和net.ipv4.tcp_tw_reuse 同时开启才能生效
net.core.somaxconn = 262144 #web应用中listen函数的backlog默认会将内核参数的net.core.somaxconn限制到128,而nginx定义的NGX_LISTEN_BACKLOG默认是511,所以必须调整
net.ipv4.tcp_fin_timeout = 30 #表示如果套接字由本端要求关闭,这个参数决定了它保持在FIN-WAIT-2状态的时间。
net.ipv4.tcp_keepalive_probes = 3
net.ipv4.tcp_keepalive_intvl = 10
net.ipv4.tcp_max_syn_backlog = 262144 #表示SYN队列的长度,默认为1024,加大队列长度为262144,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 262144 #表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息
net.core.netdev_max_backlog = 262144 #每个网络接口接收数据包的速率比内核处理这些包的速率快时,允许送到队列的数据包的最大数目
sysctl -p 执行内核参数生效
几分钟后看FIN_WAIT2明显减少
ss -s
Total: 4540 (kernel 4691)
TCP: 33564 (estab 4463, closed 25651, orphaned 3428, synrecv 0, timewait 25651/0), ports 355
Transport Total IP IPv6
* 4691 – –
RAW 0 0 0
UDP 7 7 0
TCP 7913 7913 0
INET 7920 7920 0
FRAG 0 0 0
最后推荐一把Web应用防火墙 ,为您业务保驾护航

关于在线迁移
CVM在线迁移
适用场景
在线迁移适用于以下场景(包括但不限于):
lIT架构上云
l混合云架构部署
l跨云迁移
l跨账号或跨地域迁移
与离线迁移的区别
离线迁移需要先将源端服务器的系统盘或数据盘制作成镜像,再将镜像迁移至您指定的云服务器或云硬盘。而在线迁移无需制作镜像,直接在源端服务器运行迁移工具,即可将源端服务器迁移至指定的腾讯云云服务器。
准备事项
l已在腾讯云上准备好账号和目的服务器。
l建议暂停源端服务器上的应用程序,以避免迁移时对现有应用程序可能产生的影响。
l下载 迁移工具压缩包。
支持的操作系统
目前在线迁移工具支持的源端主机操作系统包括但不限于以下操作系统(32位或64位均可):
| Linux 操作系统 | Windows 操作系统 |
|---|---|
| CentOS 5/6/7 | – |
| Ubuntu 10/12/14/16/18 | |
| Debian 7/8/9 | |
| SUSE 11/12/15 | |
| openSUSE 42 | |
| Amazon Linux AMI | |
| Red Hat 7/8 |
压缩包文件说明
| 文件名 | 说明 |
|---|---|
| go2tencentcloud_x64 | 64位 Linux 系统的迁移工具可执行程序。 |
| go2tencentcloud_x32 | 32位 Linux 系统的迁移工具可执行程序。 |
| user.json | 迁移时源端主机和目标云服务器的配置文件,请根据 user.json 文件参数说明 修改配置。 |
| client.json | 迁移工具的配置文件,请根据 client.json 文件参数说明 修改配置。 |
| rsync_excludes_linux.txt | rsync 配置文件,排除 Linux 系统下不需要迁移的文件目录。 |
迁移架构
公网迁移模式(上云)
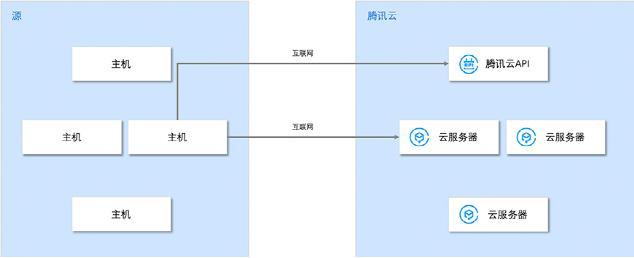
内网迁移模式 (云内)
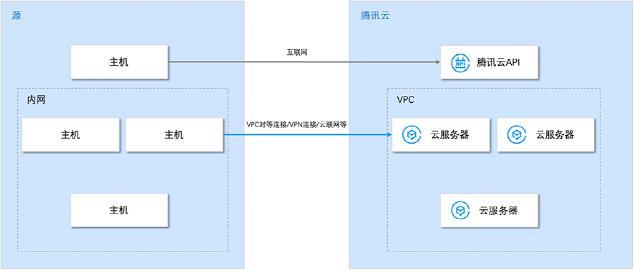
在线迁移最佳实践
迁移准备事项
建议暂停源端服务器上的应用程序,以避免迁移时对现有应用程序可能产生的影响。
下载 迁移工具压缩包。
配置迁移信息
在源端下载迁移包解压配置迁移参数
tar zxvf qztx-cyou-mergebak-move_2020-02-25-1046.tgz #解压迁移包
cd go2tencentcloud #进入工具目录
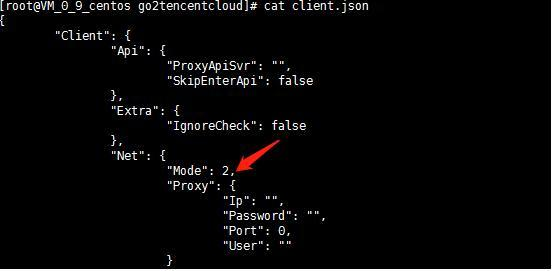
vi user.json #编辑配置文件
¡例如,将一台 Linux 源端主机迁移至腾讯云广州地域的一台云服务器中,user.json 文件配置为以下
{
“SecretId”: “your secretId”,
“SecretKey”: “your secretKey”,
“Region”: “ap-guangzhou”,
“InstanceId”: “your instance id”
}
| 参数名称 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| SecretId | String | 是 | 账户 API 访问密钥 SecretId,详细信息请参考 访问密钥。 |
| SecretKey | String | 是 | 账户 API 访问密钥 SecretKey,详细信息请参考 访问密钥。 |
| Region | String | 是 | 目标云服务器的地域,只需填写地域,无需填写可用区,取值请参考 地域 列表。 |
| InstanceId | String | 是 | 目标云服务器的实例 ID,形如ins-xxxxxxxx。 |
| DataDisks | Array | 否 | 源端主机待迁移数据盘列表,每一个元素代表一块数据盘,最多支持20块数据盘。 |
| DataDisks.Index | Integer | 是 | 源端数据盘序号,取值范围[1,20],值为1代表该块数据盘将迁移至目标云服务器的第一块数据盘,以此类推。 |
| DataDisks.Size | Integer | 是 | 源端数据盘大小,单位GB,取值范围[10,16000]。 |
| DataDisks.MountPoint | String | 是 | 源端数据盘挂载点,如”/mnt/disk1″。 |
执行迁移检测
sudo ./go2tencentcloud_x64 –check

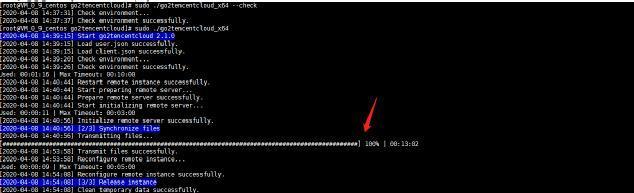
执行在线迁移
sudo ./go2tencentcloud_x64
公网无上限迁移花费时间:17分钟33秒


内网1.5G带宽迁移花费时间:13分钟2秒
迁移后的检查
迁移后需重启一次
检查网络通信情况
检查数据完整性
检查应用完整性

关于主机安全
必备要求
l禁止镜像存在公开可利用的且已公布修复方案的高危安全漏洞。
l禁止使用官方已停止维护的发行版本进行镜像,例如 Debian6、CentOS4、Win2003。
l镜像制作时必须安装所有官方安全更新,具体请参见下文 安装系统安全更新。
l禁止镜像默认安装任何病毒、木马、后门、挖矿以及挂机等恶意程序。
l禁止使用任何盗版或者破解版程序。
注意:
已上架镜像会被定期扫描,若发现服务镜像不满足上述条件存在安全漏洞或违规行为,腾讯云将有权对厂商镜像做下架处理。
优化建议
安装系统安全更新
lWindows 系列镜像:建议开启 Windows Update 自动更新,保证最新更新已安装。
l红帽系列镜像:包括 RHEL、CentOS、OpenSUSE 等,请使用 yum update 命令进行 重要安全组件 更新。
lDebian 系:包括 Debian、Ubuntu 等 Linux 发行版,在配置好正确的 APT 镜像源地址的情况下,可使用 apt update &&apt upgrade 命令进行更新。
l其他发行版包括 BSD 衍生版,请使用相应的命令进行更新。
更新常用核心组件
需确保如下组件已更新且无漏洞,更新方法可参系统安全更新所提命令:
| 内核及引导 | grub、kernel、initramfs、sysvinit、systemd、efistub 等 |
|---|---|
| 常用依赖库 | libc6、glibc、libssl(openssl)、libgnutls、OpenJDK、SunJDK、libtomcat、libxml、libgd、libpng、zlib、libpython、libnet、libkrb、libcup、libfuse、libdbus 等 |
| 常见应用 | 包含但不限于 wget、rsync、curl、tar、apt、dpkg、rpm、yum 、sshfs、shell(bash、zsh、csh、dash…)、openssh、ftp、gzip、sudo、su、ppp、exim 等 |
系统配置安全
除系统自身漏洞以及引入的第三方组件漏洞外,另一方面的威胁来自于安全配置失误导致的安全问题,通过对系统及重点组件进行加固,可以大大降低人为配置失误或弱配置导致的入侵风险。
必备要求
l禁止系统及应用高危端口默认对外网开放,常见高危端口列表见附表。
l合理配置系统关键目录的权限,例如 /etc、/bin、~/.ssh 等。
l除了/tmp 目录,其他目录不允许出现 777 权限。
l默认日志服务保证正常运行,如 dmesg、syslog、wtmp、btmp、sudo 等。
l设置合理的防火墙或安全组策略,屏蔽不安全的端口(如137、139、445等,详见如下表格),仅开放需要的端口;建议使用 iptables 默认屏蔽所有端口,单独开放需要的端口,例如 HTTP80、SSH22、RDP3389、HTTPS443 等。
附表:
| Rlogin | 513 | Rlogin 空密码登录 |
|---|---|---|
| MySQL | 3306 | MySQL 弱口令及高危漏洞 |
| SQL Server | 1433、1434 | SQL Server 弱口令及高危漏洞 |
| Windows | SMB 137、139、445 | 永恒之蓝漏洞,SMB 漏洞 |
| Rsync | 873 | Rsync 未授权访问漏洞 |
| Docker | 2375 | Docker Remote API 未授权访问漏洞 |
| CouchDB | 5984 | CouchDB 未授权访问漏洞导致系统命令执行 |
| Redis | 6379 | Redis 未授权漏洞 |
| Tomcat | 8080 | Tomcat/WDCP 主机管理系统,默认弱口令 |
| Easticsearch | 9200 | ElasticSearch 命令执行漏洞 |
| Memcached | 11211 | Memcached 未授权访问 |
| Mongodb | 27017、27018 | MongoDB 未授权访问 |
| Hadoop | 50070、50030 | Hadoop 默认端口未授权访问 |
Linux 口令策略加固
| 检查方法 | 使用命令cat /etc/login.defs/grep PASS和cat /etc/pam.d/system-auth查看密码策略设置 |
|---|---|
| 加固方法 | 1.使用命令“vi /etc/login.defs”修改配置文件 PASSMAX_DAYS 90 #新建用户的密码最长使用天数 PASS_MIN_DAYS 0 #新建用户的密码最短使用天数 PASS_WARN_AGE 7 #新建用户的密码到期提前提醒天数 使用 chage 命令修改用户设置,例如: chage -m 0 -M 30 -E 2000-01-01 -W 7 <用户名> 表示:将此用户的密码最长使用天数设为30,最短使用天数设为 0,密码 2000 年 1 月 1 日过期,过期前 7 天里警告用户 2.设置连续输错 10 次密码,账号锁定 5 分钟 使用命令vi /etc/pam.d/system-auth修改配置文件,添加auth required pam_tally.so onerr=fail deny=10 unlock_time=300 注:解锁用户 faillog -u <用户名> -r |
| 回退方法 | vi /etc/login.defs和vi /etc/pam.d/ system-auth,将配置改回加固前配置 |
| 备注 | 锁定用户功能谨慎使用,密码策略对 root 不生效 |
| 检查方法 | 对于采用静态口令认证技术的设备,应配置用户口令最小长度不小于 8 位。 |
|---|---|
| 加固方法 | 1.参考配置操作 在文件/etc/login.defs中设置PASS_MIN_LEN不小于标准值 8 |
| 检测方法 | 1.判定条件 密码长度小于8位修改密码不成功。 2.检测操作 用要修改密码的用户先登录系统,然后用 passwd 命令修改密码,当长度小于提示错误:BAD PASSWORD: it is too short |
| 回退方法 | 修改/etc/login.defs,PASS_MIN_LEN密码长度改回为 0 |
| 备注 | / |
配置防火墙限制指定源 IP 或者网段才能登录
| 1.Iptables -A INPUT -s 192.168.0.0/24 -m state –state NEW -p tcp –dport 22 -j ACCEPT 2. 这里192.168.0.0/24 可以改为自身已知网段地址 |
|---|
禁止空密码账户登录
| 1.Vi /etc/ssh/sshd_config 2. 找到 PermitEmptyPasswords 项,将其改为 no,即不允许空密码存在。 |
|---|
Linux 高危端口加固
相应服务开启后,查看是否还有高危端口开放
| 1. netstat -anltp 2.若存在非业务端口对外网开放(监听0.0.0.0:XXX),可关闭相应服务或端口所对应进程。 |
|---|
Linux 敏感文件加固
| 1. 具有 suid 和 sgid 的文件具有相当的危险性。简单说就是普通用户使用这些命令时可以具有超级用户的权限,检查特殊权限位文件命令:find /usr/bin/chage /usr/bin/gpasswd /usr/bin/wall /usr/bin/chfn /usr/bin/chsh /usr/bin/newgrp /usr/bin/write /usr/sbin/usernetctl /usr/sbin/traceroute /bin/mount /bin/umount /bin/ping /sbin/netreport -type f -perm +6000 2>/dev/null 2. 如果存在输出结果,则使用 chmod 755 文件名命令修改文件的权限。例如:chmod a-s /usr/bin/chage。 |
|---|
优化建议(Windows)
修改远程桌面默认端口
| 基线说明 | 不能使用默认的端口3389。 |
|---|---|
| 操作指南 | 1. 参考配置操作 打开命令提示符,运行命令regedit打开注册表编辑器,浏览到路径HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp,修改名称为 “PortNumber” 的数值的数据,使其不等于默认值3389。 2. 补充操作说明 需要重启系统才能生效。 |
| 检测方法 | 1. 判定条件 在其它的 Windows 上,不能仅使用 IP 通过远程桌面连接程序连接被检查计算机。 2.检测操作 打开命令提示符,运行命令regedit打开注册表编辑器,浏览到路径HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Terminal Server\WinStations\RDP-Tcp,查看 “PortNumber” 的数值的数据是否等于默认值3389。 |
配置 Windows 密码策略
| 检查方法 | 在组策略中找到密码策略选项,根据自身要求进行配置 |
|---|---|
| 加固方法 | 1. 参考配置操作 打开命令提示符,运行命令gpedit.msc打开组策略编辑器,浏览到路径“本地计算机策略\计算机配置\ Windows 设置\安全设置\帐户策略\密码策略”,配置“密码最长存留期(使用期限)”、 “密码最短存留期(使用期限)”、“密码长度最小值”、“强制密码历史”为指定值,并启用“密码复杂性要求”。 2. 推荐设置如下: 1.账户策略->密码策略 密码必须符合复杂性要求:启用 密码长度最小值:8 个字符 密码最短使用期限:0天 密码最长使期限:90天 强制密码历史:1 个记住密码 用可还原的加密来存储密码:已禁用 2.账户设置->账户锁定策略 帐户锁定时间:30 分钟 帐户锁定阈值:10 次无效登录 重置帐户锁定计数器:30分钟 3.本地策略->安全选项 交互式登录:不显示最后的用户名:启用 |
| 检测方法 | 1. 判定条件 设置新密码时有以下限制:不能设置不符合复杂性要求的密码,不能设置太短的密码,不可在最短留存期内修改密码,必须在最长留存期后修改密码,不能循环使用指定次数之内的密码。 |
删除 Windows 无关账户
| 检查方法 | 在组策略中找到安全选项,禁用来变账户或系统其他无关账户 |
|---|---|
| 加固方法 | 1. 参考配置操作 1.1.打开命令提示符,运行命令gpedit.msc打开组策略编辑器,浏览到路径“本地计算机策略\计算机配置\ Windows 设置\安全设置\本地策略\安全选项”。 1.2. 删除或锁定无关帐户,操作如下:使用 “net user 帐户名 /del” 删除无关账户 使用 “net user 帐户名 /active:no” 锁定无关账户 |
| 检测方法 | 1. 判定条件 已禁用来宾帐户,或者已删除或锁定其它与实际需求无关的帐户。 |
配置 Windows 事件审核
| 检查方法 | 在组策略中找到安全选项, 修改审核策略配置 |
|---|---|
| 加固方法 | 1. 打开命令提示符,运行命令gpedit.msc打开组策略编辑器; 2. 找到“本地计算机策略\计算机配置\ Windows 设置\安全设置\本地策略\安全选项”; 3. 推荐设置如下: 审核策略更改:成功 审核登录事件:成功,失败 审核对象访问:成功 审核进程跟踪:成功,失败 审核目录服务访问:成功,失败 审核系统事件:成功,失败 审核帐户登录事件:成功,失败 审核帐户管理:成功,失败 |
| 检测方法 | 2. 判定条件 已禁用来宾帐户;已删除或锁定其它与实际需求无关的帐户。 |
| 备注 | 3. 为避免日志空间不足,可提升日志存储空间,通过“开始”-> ”运行” ->eventvwr.msc ->“windows 日志”->查看“应用程序”“安全”“系统”的属性进行配置,推荐设置为20480KB 或更高。 |
优化 Windows 启动服务
| 检查方法 | 打开“控制面板”,打开“管理工具”中的“服务”,以不影响业务为前提,禁用以下服务: Alerter 服务 Clipbook 服务 Computer Browser Messenger Remote Registry Service Routing and Remote Access Simple Mail Trasfer Protocol(SMTP) (可选) Simple Network Management Protocol(SNMP) Service (可选) Simple Network Management Protocol(SNMP) Trap (可选) Telnet World Wide Web Publishing Service (可选) Print Spooler Terminal Service |
|---|---|
强化网络访问控制权限
| 检查方法 | 启动网络访问控制 操作方法如下: 【开始】>【运行】>【secpol.msc】>【安全设置】>【本地策略】>【安全选项】 推荐配置如下: 网络访问:不允许 SAM 帐户的匿名枚举:已启用 网络访问: 不允许 SAM 帐户和共享的匿名枚举:已启用 网络访问:将 Everyone 权限应用于匿名用户:已禁用 帐户: 使用空密码的本地帐户只允许进行控制台登录:已启用 关闭共享服务端口(135、137、139、445 等) 若未用到 SMB、RPC 等服务,建议用户关闭相应服务端口 135 端口关闭方法: 1.单击“开始”——“运行”,输入“dcomcnfg”,单击“确定”,打开组件服务。 2.在弹出的“组件服务”对话框中,选择“计算机”选项。 3.在“计算机”选项右边,右键单击“我的电脑”,选择“属性”。 4.在出现的“我的电脑属性”对话框“默认属性”选项卡中,去掉“在此计算机上启用分布式 COM”前的勾。 5.选择“默认协议”选项卡,选中“面向连接的 TCP/IP”,单击“删除”按钮。 6.单击“确定”按钮,设置完成,重新启动后即可关闭 135 端口 137、138、139等 Netbios 服务端口关闭方法 【控制面板】 >【网络与共享中心】>【本地连接】右击属性,选择“TCP/IPv4协议”,属性,在“常规”选项卡下选择“高级”,选择“WINS”选项卡,选中“禁用 TCP/IP 上的 NetBIOS”,这样即关闭了 139 端口。 具体操作可参考 这里 关闭默认共享 |
|---|---|
第三方组件安全
第三方组件为各类 Web 类应用服务提供丰富的支撑环境,如果爆发漏洞,会给操作系统本身以及用户的业务带来极大的风险和隐患,对第三方的组件进行加固,可以保服务组件整体的安全性,以及保障服务自身安全及用户信息安全。
必备要求
l禁止镜像第三方组件存在公开可利用的且已公布修复方案的安全漏洞。
l禁止使用已停止维护的软件版本,如 PHP 5.3. 与 5.4.版本、PHPMyadmin 4.0.0 以下版本,MySQL 5.1 版本等。
l镜像制作中需从第三方组件官方提供的下载页面下载最新稳定版本进行安装,禁止通过非官方站点下载部署。
l禁止使用任何非授权或破解版商业程序提供商业服务。
l涉及到镜像内置的软件功能(包括但不限于数据库,FTP,商业软件)的密码,均不能使用“默认方式”内置到镜像文件内,而是通过“启动脚本”的方式(shell,cloud-init 等方案)在镜像创建云服务器的过程随机生成密码文件,客户在拿到云服务器的访问权限后,可通过 SSH 或者远程桌面等自行去云服务器上查找密码文件以获得密码;生成密码文件的脚本必须使用随机算法,保证每次云机创建后获得的都是唯一的密码。
用自定义的错误页面替换默认的默认页面。
MySQL 安全优化建议
修改 MySQL 网络监听地址
MySQL 默认配置为绑定所有的 IP,服务器有外网可以被外网访问。为安全起见必须绑定内网 IP,不允许外网访问,可编辑配置文件 my.cnf,在 mysqld 选项中增加一项:
bind_address = 172.16.x.x
后面的ip地址代表需要绑定的内网 IP 地址。
修改 MySQL 默认端口
更改默认端口(默认3306),可以从一定程度上防止端口扫描工具的扫描
编辑
/etc/my.cnf
文件,增加端口参数,并且设定端口,注意该端口未被使用,保存退出。如:
l
[mysqld]
port=3806
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
非 Root 帐户运行 MySQL
首先必须要使用独立的受限账户启动 MySQL,一般是系统中存用户名和用户组均为 MySQL 的账户,同时把配置文件拷贝到
/etc
目录。使用 MySQL 来启动 MySQL 服务:
/usr/local/mysql/bin/mysqld_safe –user=mysql &
MySQL Root 账户设置密码
5.6 中,rpm 包安装完 MySQL 后,会随机生成一个 root 密码,保存在
/root/.mysql_secret
5.5 以前,rpm 包安装完 MySQL 后,缺省管理员账户的密码为空,需要对该账户设置密码,可以采用如下办法设置管理员密码:
mysql> use mysql;
mysql> update user set password=password(‘upassword’) where user=’root’;
mysql> flush privileges;
删除默认数据库及用户
MySQL 初始化后会自动生成空用户和 test 库,会对数据库安全构成威胁,需要全部删除。可采用如下方法:
mysql>drop database test;
mysql>use mysql;
mysql>delete from db;
mysql>delete from user where not(host=”localhost” and user=”root”);
mysql>flush privileges;
控制远程连接
由于 MySQL 是可以远程连接的,需要控制远程连接的范围,如仅内网访问或不允许网络访问。禁止任意远程账户连接。 可以采用如下方式或者通过防火墙来限制 MySQL 的远程访问。
mysql> show grants for username; //显示账户权限
mysql> grant all on dbname.* to ‘username’@’ip地址’ identified by ‘密码’;
控制数据库的权限
对于使用 Web 脚本进行交互的数据库,建议建立一个用户只针对某个库有 update、select、delete、insert、drop table、 create table 等权限,减小数据库的用户名和密码被黑客窃取后的影响和损失。控制数据库的权限可参考如下:
Mysql> grant select,insert,update,delete,create,drop privileges on dbname.* To user1@localhost identified by ‘密码’;
数据库名,账户及密码需要根据实际情况填写。
文件读写权限控制
在 Mysql 中,提供对本地文件的读取,使用的是
load data local infile
命令,默认在5.0版本中,该选项是默认打开的,该操作令会利用 MySQL 把本地文件读到数据库中,然后用户就可以非法获取敏感信息了,假如您不需要读取本地文件,请务必关闭。
网络上流传的一些攻击方法中就有用它
LOAD DATA LOCAL INFILE
的,同时它也是很多新发现的 SQL Injection 攻击利用的手段!黑客还能通过使用
LOAD DATALOCAL INFILE
装载
“/etc/passwd”
进一个数据库表,然后能用 SELECT 显示它,这个操作对服务器的安全来说,是致命的。
在 my.cnf 中添加:
local-infile=0
或者加参数
local-infile=0
启动 MySQL。
Redis 安全优化建议
安装下载
使用最新稳定版本,最新版的安全性更高。下载安装命令如下:
wget http://download.redis.io/redis-stable.tar.gz
tar zxvf redis-stable.tar.gz
cd redis-stable
make && sudo make install
安全启动
lRedis 配置文件里参数至少包括 requirepass 设置访问密码和 bind 只监听内网 IP,以减少安全风险。更改配置命令如下:
echo “requirepass 密码” >> /etc/redis.conf
echo “bind 内网IP地址” >> /etc/redis.conf
注意:
密码长度至少8位,且同时包含大小写字母和数字;内网 IP 地址请自行修改。
l新建普通用户 Redis 用于降权启动服务,相关命令参考如下:
l
useradd redis -d /home/redis -m #新建普通用户
chown redis:redis /etc/redis.conf #修改配置文件属主
chmod 700 /etc/redis.conf #修改配置文件权限
su – redis #切换至普通用户
redis-server /etc/redis.conf #启动服务
修改默认端口
修改 Redis 默认端口6379为其他端口,打开配置文件
redis.conf
,如:
vim /etc/redis.conf
将 port 6379修改为 port xxxx。
端口限制访问
遵循最小化原则,按需分配访问权限,以减少安全风险。Iptables 命令参考如下:
iptables -A INPUT -p tcp -s 来源IP地址 –dport 6379 -j ACCEPT
iptables -A INPUT -p tcp –dport 6379 -j DROP
注意:
来源 IP 地址请自行修改;Redis 默认监听端口为6379(TCP),若业务修改成其他端口,这里也要作对应修改。
限制 Redis 文件目录访问权限:
设置 Redis 的主目录权限为700,因为 Redis 密码明文存储在配置文件当中,所以配置文件存放的目录权限修改为600。命令参考如下:
chmod 700 /opt/redis 、chmod 600 /opt/redis/conf
MongoDB 安全优化建议
安装下载:
使用最新稳定版本,最新版的安全性更高。最新版下载地址:
http://www.mongodb.org/downloads
安全配置方案
1.创建 mongodb 数据库文件夹:
mkdir /mongodb/db
2.创建 mongodb 日志文件:
touch /mongodb/log/mongodb.log
3.启动 mongodb 时需要添加— auth 参数,并立即在 admin 数据库创建一个用户(默认情况下 MongoDB 是无需验证的,所以这是至关重要的一步)
./mongod –dbpath /mongodb/data –logpath /mongodb/log/mongodb.log –nohttpinterface –auth
4.启动的时候需要加上– nohttpinterface 参数取消默认 Web 管理页面。
5.非 root 权限启动 mongodb,在机器上登录非 root 账户,给予 mongodb 程序和数据库文件夹,日志文件的该账户读写执行权限。
端口限制访问
iptables -A INPUT -p tcp -s 来源IP地址 –dport 27017 -j ACCEPT
iptables -A INPUT -p tcp –dport 27017 -j DROP
说明:
来源 IP 地址请自行修改;mongodb 默认监听端口为27017,若业务修改成其他端口,请做对应修改。且 monggodb 端口禁止对外网访问。
文件目录限制
l配置文件只允许属主读取和修改、属组读取。
chmod 640/usr/local/mongodb/mongodb.conf
l数据目录只允许属主读取和修改。
chmod 700 /usr/local/mongodb/data/
l日志文件目录只允许属主读取和修改、属组读取。
chmod 740 /usr/local/mongodb/log/
vsFTPd 安全优化建议
安装部署:
在
http://vsftpd.beasts.org/#download
下载最新版 vsftp 源码包,编译安装。
关闭匿名访问功能:
如业务无必要,可关闭匿名访问功能,修改 VSFTP 配置文件 vsftpd.conf,修改以下配置,关闭匿名访问:
anonymous_enable=NO
禁止 VSFTP 显示 Banner,防止泄漏版本信息:
登录 FTP 服务器,查看是否显示 Banner:
l
C:>ftp 192.168.10.1
Connected to 192.168.10.1
220 (vsftpd 2.0.5)
User (192.168.10.1:(none)):
修改 VSFTP 配置文件 vsftpd.conf,修改以下语句:
l
ftpd_banner=Welcome
重新启动 VSFTP 后,查看 Banner:
l
C:>ftp 192.168.10.1
Connected to 192.168.10.1
220 Welcome
User (192.168.10.1:(none)):
如允许匿名用户上传文件,建议配置只写目录:
找到
/ var/ftp/pub
目录,通过如下命令创建只写目录:
mkdir /var/ftp/pub/upload_files
限制 FTP 匿名用户访问上传文件目录:
chmod 730 /var/ftp/pub/upload_files
开启日志记录:
修改 VSFTP 配置文件 vsftpd.conf,修改以下行,启用日志记录:
l
xferlog_enable=YES
xferlog_file=/var/log/xferlog
dual_log_enable=YES
vsftpd_log_file=/var/log/vsftpd.log
use_localtime=YES
SFTP 默认只有上下传记录,没有用户登录等信息的记录。按照上述加固方法,可以在
/var/log/vsftpd.log
查看用户登录记录,创建目录删除目录等信息。
主机挖矿场景处理
第一步:系统做镜像和快照
第二步:清理挖矿木马病毒
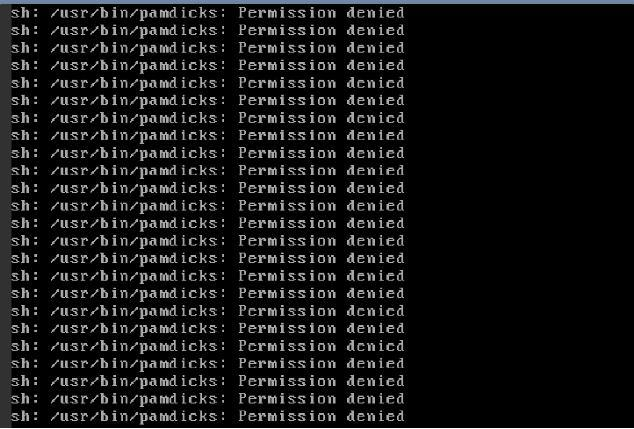
安装 unhide 清理扫描隐藏进程
准备busybox、pam_unix.so文件;
#安装unhide备用
yum install unhide -y ;
#修复登录模块 & 清理后门程序
mv /lib64/security/pam_unix.so /lib64/security/pam_unix.bak
#拷贝正常登录文件进去
cp pam_unix.so /lib64/security/pam_unix.so
#检查隐藏进程pid
unhide quick
#kill掉所有隐藏进程
busybox kill -9 pids;
#清理所有恶意程序
busybox rm -f /usr/bin/pamdicks /bin/pamdicks /usr/bin/kswaped /usr/bin/irqbalanced /usr/bin/rctlcli /usr/bin/systemdnetwork /lib/udev/ssd_control/iproute.ko /lib/udev/ssd_control/cryptov2.ko /lib/udev/ssd_control/netlink.ko /usr/bin/kaudited /usr/bin/pamdicks.org
注意:挖矿清理后需要进行一次重启,释放驱动插入内存里缓存数据
第三步:系统加固业务解耦
创建一个纯净版的系统,然后部署应用,系统加固后制作用自定义镜像,方便后续快速创建新机器
镜像安全审核标准系统加固
1.创建新机器搬迁业务,提供游戏服对外服务,完成业务和自建DB解耦
2.摘掉挖矿机器公网IP,提供数据库内网服务,完成业务和自建DB解耦
3.自建数据库DTS上云,提供数据库内网服务,完成业务和DB解耦
第四步 : 主机安全整改建议
1.CVM替换现有ssh登陆密钥
2.安全组关闭端口全开放,只开放业务端口
- 建议用户定期更新密码,使用堡垒机登录管理
4.系统日志ES集中保存,方便溯源
5.部署主机安全防护对常见木马及时检测
6.代码上线前集中扫描是否存在漏洞
FAQ
vmocre分析
- wget http://mirrors.tencentyun.com/centos-debuginfo/6/x86_64/kernel-debuginfo-2.6.32-696.el6.x86_64.rpm
-
rpm2cpio ./kernel-debuginfo-common-x86_64-3.10.0-957.21.3.el7.x86_64.rpm |cpio -idm
-
crash vmcore_193.112.124.55 /root/usr/lib/debug/lib/modules/2.6.32-696.el6.x86_64/vmlinux
(可能涉及yum install crash -y 通过 find / -name vmlinux 确定vmlinux路径)
关于数据备份
数据备份最佳实践:
l创建快照&从快照回滚数据
快照是对云硬盘的完全可用拷贝。当已创建快照的云硬盘出现问题时,可通过快照快速恢复到未出问题前的状态。
Ø创建快照:
(2)单击目标云硬盘所在行右侧的【创建快照】。如下图所示:
(3)在弹出的【创建快照】对话框中,输入快照名称,并单击【提交】。
Ø从快照回滚数据:
参考文档:
操作方法:
(1)登录 快照列表 页面。
(2)单击目标快照所在行的【回滚】。(注:源云硬盘的数据将回滚到创建快照时刻的数据,此时刻之后的数据将被清除,请谨慎操作!)
(3)在“回滚数据”页面中,确认回滚信息并单击【确定】即可开始回滚。
l创建自定义镜像
自定义镜像会记录服务器系统盘中的系统环境及数据,系统盘自定义镜像可以用于服务器的重装,以恢复到之前的系统状态;也可以用于新建服务器,以快速复制系统环境等。
操作方法:
(1)登录 云服务器控制台。
(2)在实例的管理页面,选择需要制作镜像的实例,单击【更多】>【实例状态】>【关机】。
(3)待实例关机后,在该台实例行中,单击【更多】>【制作镜像】
(4)在弹出的 “制作自定义镜像” 窗口中,输入 “镜像名称” 和 “镜像描述”,单击【制作镜像】,进行创建。
(5)待镜像完成创建后,单击左侧导航栏中的【镜像】,进入镜像管理页面。
(6)在镜像列表中,选择您创建的镜像,单击【创建实例】,即可购买与之前相同镜像的服务器
l定期快照策略
腾讯云云硬盘 快照 自助开放了定期快照功能,该功能便于开发者灵活设置备份任务策略。
建议针对不同业务采用不同的定期快照策略,推荐设置如下表:
| 业务场景 | 快照频率 | 快照保留时间 |
|---|---|---|
| 核心业务 | 使用定期快照,策略设置为每天1次 | 7天 – 30天 |
| 非核心、非数据类业务 | 使用定期快照,策略设置为每周1次 | 7天 |
| 归档业务 | 根据实际业务需求手动制作快照,无需设置固定频率 | 一个月到数个月 |
| 测试业务 | 根据实际业务需求手动制作快照,无需设置固定频率 | 用完及时删除 |
【注】:
对于重要的快照,依然建议永久保留,将快照转为永久保留的快照的操作方法:
(1)登录 快照列表 页面。
(2)选择地域。
(3)单击目标自动快照的 ID。
(4)在详情页中,单击【长期保存】,将自动快照设置为永久保留。
Ø创建定期快照策略
(1)登录定期快照策略 页面
(2)选择地域。
(3)单击【新建】。如下图所示:
(4)在“新建快照策略”页面中,设置名称、所属地域、备份日期、备份时间点、快照保留时间,然后单击【确定】
Ø定期快照策略关联云硬盘
(1)登录 定期快照策略 页面。
(2)选择地域。
(3)单击目标策略所在行的【关联云硬盘】。
(4)在“关联云硬盘”页面中,勾选需要关联的云硬盘。
(5)单击【确定】。
Ø开启/关闭定期快照策略
(1)登录 定期快照策略 页面。
(2)选择地域。
(3)找到目标策略所在行,单击“定期快照”栏下的开关按钮即可开启或关闭该定期快照策略。
Ø修改定期快照策略
(1)登录 定期快照策略 页面。
(2)选择地域。
(3)单击目标策略所在行的【修改策略】。
(4)在“修改快照策略”页面中,修改相关参数(参数说明请参考 步骤4)并单击【确定】。
Ø注意事项:
(1)、定期快照策略必须关联了云硬盘并处于开启状态才会生效。
(2)、必须保证账户余额充足(余额不为负),定期快照策略才能正常生效。若账号欠费,则定期快照策略将会自动停止生效。
关于置放群组
何为置放群组
置放群组是实例在底层硬件上分布放置的策略,您在置放群组中创建的实例在启动时就具备容灾性和高可用性。
腾讯云云服务器提供的实例置放策略,可在创建时将实例以某种策略强制打散,以降低底层硬件/软件故障给云服务器上业务带来的影响。
您可以使用置放群组将业务涉及到的云服务器实例分散部署在不同的物理服务器上,以此保证业务的高可用性和底层容灾能力。
分散置放群组规则和限制
在使用分散置放群组之前,请注意以下规则:
1.不能合并置放群组。
2.一次可在一个置放群组中启动一个实例。
3.实例不能跨多个置放群组。
4.可选择分散置放层级:物理机、交换机、机架三个层级。
5.不同置放层级的群组最多支持实例不同,具体数值视官网页面为准。
6.使用容灾组策略后,会严格遵守您指定的策略。特别注意的是,如底层硬件不足够使实例分散,部分实例将创建失败。
7.专用宿主机上实例不支持分散置放群组。
创建置放群组
https://console.cloud.tencent.com/cvm/ps
物理机层级 (细颗粒度),适用于游戏服
交换机层级 (中颗粒度),适用于HA应用
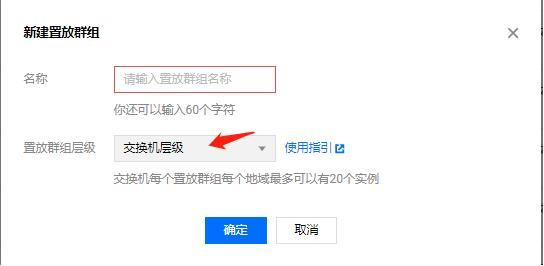
机柜层级 (高颗粒度),适用于中央服

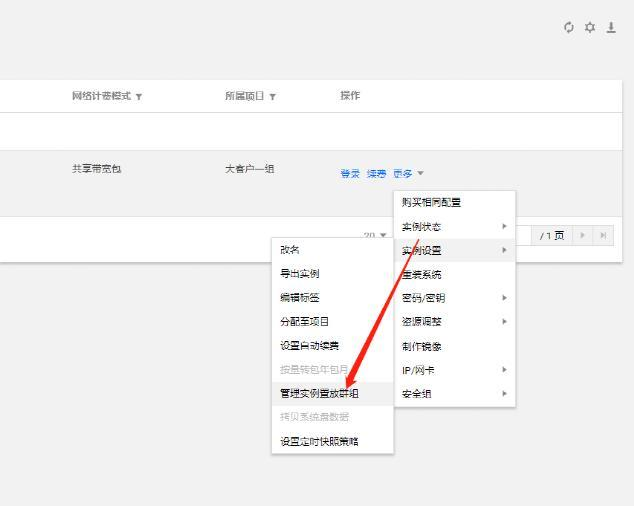
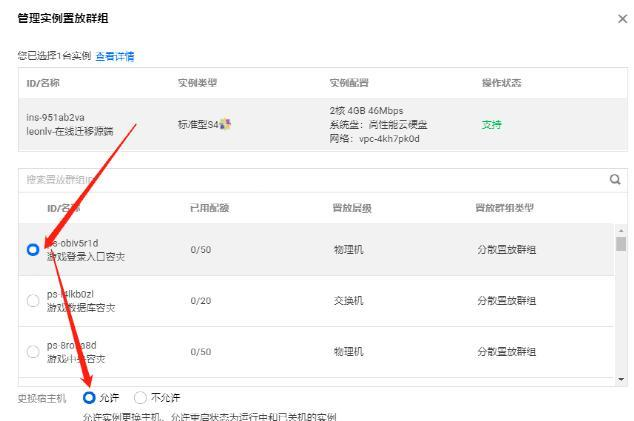
分配置放群组
登录CVM控制台—->选择实例设置—->管理实例置放群组—>分配实例置放群组
关于内核优化
最强宇宙博哥补充
内核概念基本介绍
| | |
|---|---|
| 内核概念基本介绍 | Linux内核的主要模块(或组件)分以下几个部分:存储管理、CPU和进程管理、文件系统、设备管理和驱动、网络通信,以及系统的初始化(引导)、系统调用等。 与各个内核模块对应的,Linux提供了各类配置文件用于调整系统性能。值得注意的是,内核参数的调整并没有“最优解”,只有在特定的业务场景下才有最“合适的方案”。 腾讯云提供的CVM是KVM虚拟化的虚拟机,在虚拟机中,绝大多数的内核参数与物理机是一致的,但是有极少数内核参数在虚拟化环境中,是无效的。例如:系统I/O调度算法,由于KVM环境中为虚拟机磁盘提供I/O能力的是virtio驱动,虚拟机中的I/O读写最终都是要通过virtio驱动来传递到底层,而virtio驱动在虚拟化环境中已经被定义,因此在CVM系统内部无论将磁盘调整为何种I/O调度算法,都是无效的。 |
| | |
内容
腾讯云公共镜像中涉及默认参数优化
| | |
|---|---|
| 内核概念基本介绍 | 想法观点 |
| | 填写脑暴的想法。 |
| | 想法来源 : 填写脑暴的想法的来源或思路。 |
| | |
内容
关键内核参数配置文件
| | |
|---|---|
| 内核概念基本介绍 | CPU 内存 网络 I/O 文件系统 /etc/rc.local /etc/sysctl.conf /sys/block/vdx |
| | |
1./etc/rc.local
系统启动之后第一个读取的文件,进行系统初始化
1./etc/sysctl.conf
关键的系统内核参数配置文件
2./sys/block/vdx
3./etc/security/limits.conf
limits.conf文件限制着用户可以使用的最大文件数,最大线程,最大内存等资源使用量
常见使用场景中的内核参数优化
| | |
|---|---|
| 云上常见场景 | CVM作为CLB后端实例提供服务 |
| | |
| | |
| | |
CVM作为CLB后端实例提供服务
建议:不要将 net.ipv4.tcp_timestamps 与 net.ipv4.tcp_tw_recycle 同时设置为1

场景:客户端在NAT环境下访问对应CLB可能会出现丢包、偶尔无法访问、高延时等异常现象
对应配置文件优化方法:
l修改 /etc/sysctl.conf 文件,将 net.ipv4.tcp_tw_recycle 设置为 0
lnet.ipv4.tcp_timestamps 通常情况下默认为 1
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
net.ipv4.tcp_tw_recycle—TCP快速回收是一种链接资源快速回收和重用的机制,当TCP链接进入到TIME_WAIT状态时,通常需要等待2MSL的时长,但是一旦启用TCP快速回收,则只需等待一个重传时间(RTO)后就能够快速的释放这个链接,以被重新使用。
我们在一些高并发的 WebServer上,为了端口能够快速回收,打开了tcp_tw_reccycle ,而在关闭 tcp_tw_recycle 的时候,kernel 是不会检查对端机器的包的时间戳的;打开了 tcp_tw_recycle 了,就会检查时间戳,如果很不幸发来的包的时间戳是乱跳的,就会出现把带了“倒退”的时间戳的包当作是“recycle的tw连接的重传数据,不是新的请求”,于是丢掉不回包,造成丢包。
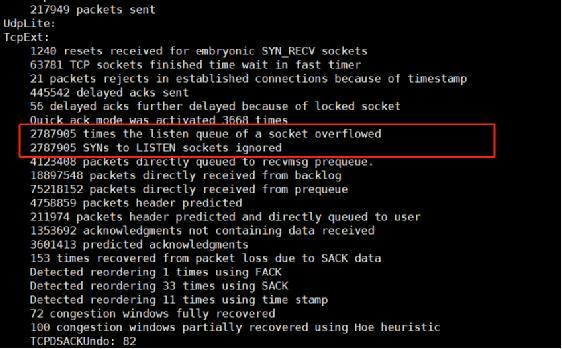
tcp全连接,半连接队列溢出
建议:系统默认的4个内核参数需要修改如下:
1.net.core.somaxconn (默认是128,需要修改为16384)

2. net.ipv4.tcp_max_syn_backlog(默认是128,需要修改为65536)

- net.core.wmem_default(默认是212992,需要修改为8388608)

- net.core.rmem_default(默认是212992,需要修改为8388608)

场景:间歇性的出现client向server建立连接三次握手已经完成,但server没有响应到该连接,造成tcp全连接队列满了,出现丢链接的情况

对应配置文件优化方法:
l修改 /etc/sysctl.conf 文件,在最后添加如下四行:
net.core.somaxconn = 16384
net.ipv4.tcp_max_syn_backlog = 65536
net.core.wmem_default=8388608
net.core.rmem_default=8388608
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
net.core.somaxconn定义了系统中每一个端口最大的监听队列的长度,这是个全局的参数,默认值为128.限制了每个端口接收新tcp连接侦听队列的大小。对于一个经常处理新连接的高负载 web服务环境来说,默认的 128 太小了。大多数环境这个值建议增加到 1024 或者更多
tcp_max_syn_backlog是指定所能接受SYN同步包的最大客户端数量,即半连接上限
net.core.wmem_default 是默认的TCP数据发送窗口大小(字节)
net.core.rmem_default是默认的TCP数据接收窗口大小(字节)
全连接队列的大小取决于:min(backlog, somaxconn) . backlog是在socket创建的时候传入的,也就是在代码里面设置的一个参数,somaxconn是一个os级别的系统参数
半连接队列的大小取决于:max(64, /proc/sys/net/ipv4/tcp_max_syn_backlog)。 不同版本的os会有些差异
vim文件描述符个数超限
建议:
1.系统的内核参数需要修改如下,保证soft nofile<=hard nofile<file-max
hard nofile<=fs.nr_open(不同版本的os默认的open files个数不同,有些是1024,需要调整)。
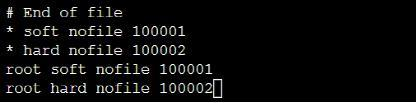

场景:在运行多线程程序时,每个线程都fopen一个文件,当达到九百多的时候程序异常退出,原因是文件句柄达到上限无法打开文件,一般会碰到”Too many open files”或者Socket/File: Can’t open so many files等错误
对应配置文件优化方法:
l修改 /etc/security/limits.conf 文件,在最后添加如下两行:
root soft nofile 100001
root hard nofile 100002
l修改/etc/sysctl.conf文件,在最后添加一行(非必须,在系统最大限制不够时再调整):
fs.file-max = 2000000
fs.nr_open = 2000000
fs.nr_open = 2000000
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
file-max 表示系统级别的能够打开的文件句柄的数量。是对整个系统的限制,并不是针对用户的。
ulimit -n 控制进程级别能够打开的文件句柄的数量。提供对shell及其启动的进程的可用文件句柄的控制。这是进程级别的。
nr_open是单个进程可分配的最大文件数
/etc/sysctl.conf fs.nr_open 的值要大于等于 /etc/sysctl.conf hard nofile 的值
/etc/security/limits.conf文件限制着用户可以使用的最大文件数,最大线程,最大内存等资源使用量
① soft nofile表示可打开的文件描述符的最大数(软限制)
② hard nofile表示可打开的文件描述符的最大数(硬限制),必定不能超过这个设定的值
lsof
如果出现了达到系统级别最大限制时,也需要同步调整系统级的最大数的。
NAT环境下,大量tcp建立连接失败
建议:
1.如果client端是在NAT的网络环境下,那么不要在server端把net.ipv4.tcp_tw_recycle设置为1
场景:
为避免server端的time-wait数过高,很多人把参数net.ipv4.tcp_tw_recycle和tcp_timestamps设置为1,也就是开启了time-wait的快速回收,然后会发现会有很多client访问不了业务,连接失败如下图
使用tcpdump抓包在卡顿的时候会抓到大量的syn请求,但服务器没有响应
对应配置文件优化方法:
l修改/etc/sysctl.conf文件,修改参数如下:
net.ipv4.tcp_tw_recycle = 0
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
net.ipv4.tcp_tw_reuse 允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭,该参数只对客户端起作用,开启后客户端在1s内回收
net.ipv4.tcp_tw_recycle 允许开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭,该参数对客户端和服务器同时起作用,开启后在 3.5*RTO 内回收,RTO 200ms~ 120s 具体时间视网络状况。
tcp_timestamp 是 RFC1323 定义的优化选项,主要用于 TCP 连接中 RTT(Round Trip Time) 的计算,开启 tcp_timestamp 有利于系统计算更加准确的 RTT,也就有利于 TCP 性能的提升。(默认开启)
开启tcp_tw_recycle会启用tcp time_wait的快速回收,tcp_tw_recycle是依赖tcp_timestamps参数的,在一般网络环境中,可能不会有问题,但是在NAT环境中,打开了 tcp_tw_reccycle 参数,内核就会检查tcp请求包的时间戳,而由于client端是NAT的网络组成,所以client发送的请求包的时间戳是乱跳的,所以server端就把带了“倒退”的时间戳的包当作是“recycle的tw连接的重传数据,不是新的请求”,于是丢掉不回包,造成大量丢包。
实际举例如下:
办公室的外网地址只有一个,所有人访问后台都会通过路由器做SNAT将内网地址映射为公网IP,由于服务端和客户端都启用了tcp_timestamps,因此TCP头部中增加时间戳信息,而在服务器看来,同一客户端的时间戳必然是线性增长的,但是,由于我的客户端网络环境是NAT,因此每台主机的时间戳都是有差异的,在启用tcp_tw_recycle后,一旦有客户端断开连接,服务器可能就会丢弃那些时间戳较小的客户端的SYN包,这也就导致了网站访问极不稳定。
主机A SIP:P1 (时间戳T0) —> Server 主机A断开后
主机B SIP:P1 (时间戳T2) T2 < T0 —> Server 丢弃
在docker环境配置web服务,使用端口映射报错
建议:
在使用docker的端口映射功能时,需要设置net.ipv4.ip_forward参数为1,然后重启网卡,代表开启了ipv4的包转发功能
场景:
在启动docker时加上端口映射报错如下,提示没有开启ipv4的包转发功能

对应配置文件优化方法:
l修改/etc/sysctl.conf文件,修改参数如下:
net.ipv4.ip_forward = 1
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
要让Linux系统具有路由转发功能,需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况;其值为0时表示禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
linux文件系统缓存内核参数优化
建议:
(1)减少cache(虚拟机的典型应用):
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
(2)增加cache(适用于数据不是很重要,但要求缓存高速读写的场景):
vm.dirty_background_ratio = 50
vm.dirty_ratio = 80
(3)增减cache兼顾(例如部署kafka集群):
vm.dirty_background_ratio = 5
vm.dirty_ratio = 80
场景:
如果cached的脏数据所占比例(这里是占MemTotal的比例)超过dirty_ratio的值,系统会停止所有的应用层的IO写操作,从而导致IO hang,等待刷完数据后恢复IO
对应配置文件优化方法:
l修改/etc/sysctl.conf文件,修改参数如下(根据具体场景选择具体参数):
vm.dirty_background_ratio = 5
vm.dirty_ratio = 10
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
vm.dirty_background_ratio:这个参数指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台回写进程运行,将一定缓存的脏页异步地刷入磁盘;
vm.dirty_ratio:这个参数则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入磁盘);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
脏页是linux内核中的概念,因为硬盘的读写速度远赶不上内存的速度,系统就把读写比较频繁的数据事先放到内存中,以提高读写速度,这就叫高速缓存,linux是以页作为高速缓存的单位,当进程修改了高速缓存里的数据时,该页就被内核标记为脏页,内核将会在合适的时间把脏页的数据写到磁盘中去,以保持高速缓存中的数据和磁盘中的数据是一致的
本地客户端可用端口不足
建议:
修改参数如下(可根据具体情况预留指定端口):
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.ip_local_reserved_ports = xxx
当前公共镜像默认参数如下:

场景:
在本地端并发的连接某个服务时,已经修改了文件句柄数,但是只能连接28231个连接就到达了瓶颈,并且每次连接都是,然后就会返回errorno = 1,随后系统内cpu负载会直线上升
对应配置文件优化方法:
l修改/etc/sysctl.conf文件,修改参数如下(根据具体场景选择具体端口范围和保留端口号):
net.ipv4.ip_local_port_range = 1024 65535
net.ipv4.ip_local_reserved_ports = xxx
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
ip_local_port_range定义了本地tcp/udp的端口范围。可以理解为系统中的程序会选择这个范围内的端口来连接到目的端口,这个参数适用于客户端
ip_local_reserved_ports系统预留端口列表,TCP/IP协议栈从ip_local_port_range中随机选取源端口时,会排除ip_local_reserved_ports中定义的端口,因此就不会出现端口被占用了服务无法启动。
nginx中tcp连接会话保持时间优化
建议:
修改参数如下(可根据具体情况调整时间间隔):
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp_keepalive_probes = 3
当前公共镜像默认参数如下:

场景:
在nginx业务的环境下,net.ipv4.tcp_keepalive_time参数时间设置过长,会导致长时间保持tcp连接状态,占用tcp连接资源数,也容易导致空连接攻击
对应配置文件优化方法:
l修改/etc/sysctl.conf文件,修改参数如下(可根据具体情况调整时间间隔):
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_keepalive_intvl = 15
net.ipv4.tcp_keepalive_probes = 3
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
net.ipv4.tcp_keepalive_time
在tcp连接状态里,有一个是established状态,只有在这个状态下,客户端和服务端才能通信。正常情况下,当通信完毕,客户端或服务端会告诉对方要关闭连接,此时状态就会变为timewait,如果客户端没有告诉服务端,并且服务端也没有告诉客户端关闭的话(例如,客户端那边断网了),此时需要该参数来判定。比如客户端已经断网了,但服务端上本次连接的状态依然是established,服务端为了确认客户端是否断网,就需要每隔一段时间去发一个探测包去确认一下看看对方是否在线。这个时间就由该参数决定。它的默认值为7200秒,高并发的情况下建议设置为1200秒或1200秒以下。
net.ipv4.tcp_keepalive_intvl
该参数和上面的参数是一起的,服务端在规定时间内发起了探测,查看客户端是否在线,如果客户端并没有确认,此时服务端还不能认定为对方不在线,而是要尝试多次。该参数定义重新发送探测的时间,即第一次发现对方有问题后,过多久再次发起探测。默认值为75秒,可以改为15秒或15秒以下。
net.ipv4.tcp_keepalive_probes
上面两个参数规定了何时发起探测和探测失败后再过多久再发起探测,但并没有定义一共探测几次才算结束。该参数定义发起探测的包的数量。默认为9,建议设置3或3以下。
Linux最大进程数内核参数优化
建议:
修改参数如下(可根据具体情况调整):
kernel.pid_max = 65535
当前公共镜像默认参数如下:

场景:
按照系统中默认的内核参数,系统最大支持进程数为32768,当系统内起的进程数满了之后就会报如下的内存不足的错误,fork:Cannot allocate memory

对应配置文件优化方法:
l修改/etc/sysctl.conf文件,添加参数如下(可根据具体情况调整):
kernel.pid_max = 65535
l修改/etc/security/limits.conf文件,添加参数如下(可根据具体情况调整):
* soft nproc 65535
* hard nproc 65535
l修改完毕后,执行 sysctl -p 使之生效
原理简介:
ulimit -a看到的max user processes (ulimit -u)是系统限制某用户下最多可以运行多少进程或线程
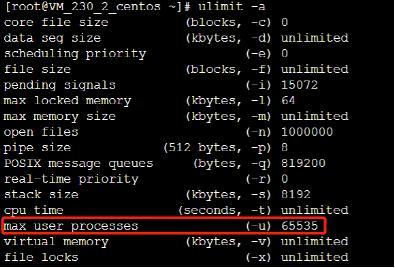
kernel.pid_max是从系统内核层面能达到的进程数的最大值
root 账号下 ulimit -u 出现的max user processes 的值默认是 # cat /proc/sys/kernel/threads-max的值/2,即系统线程数的一半
普通账号下 ulimit -u 出现的max user processes的值 默认是 /etc/security/limits.d/20-nproc.conf(centos6 是90-nproc.conf) 文件中的
linux内核开启net.ipv4.tcp_tw_recycle后端口不通,可以ping通
背景:源:183.62.194.66(客户本地)
目的:139.199.5.123 -p 9018 & 118.89.65.140 -p 22
1.公网测试telnet可以通信,ssh可以远程,
2.子机内部未开启防火墙。没有安全软件
根据抓包排查 客户侧–>(母机物理网卡)bond–>(虚拟网卡)veth–>子机内部,数据包从veth网卡发送到子机内部,子机没有回包。
客户侧抓包:
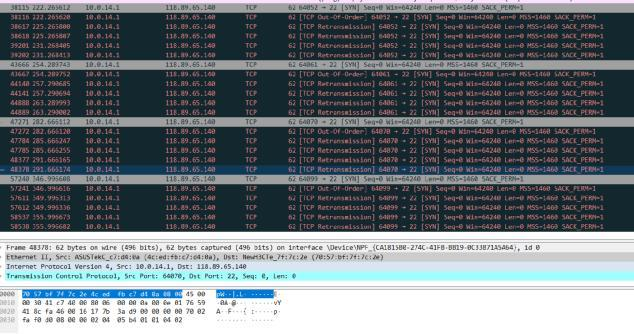
母机(bond和veth)抓包
1.
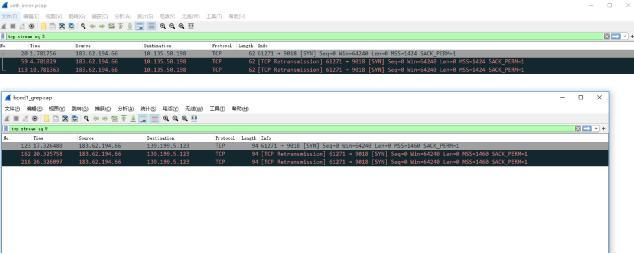
检查路由有没有针对这个ip的特殊配置,未存在ip限制
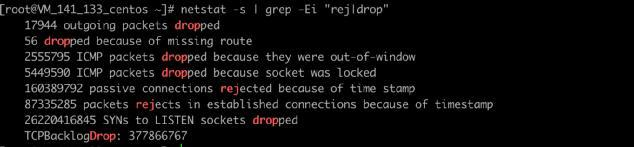
2.检查是不是内核有丢包,内核丢包这里就很多了,常见的就是netstat -s看,160389792 passive connections rejected because of time stamp
3.检查内核参数,客户开启了net.ipv4.tcp_tw_recycle这个内核设置,会导致他们ssh过来的时候,因为tcp时间戳不对被拒绝,其他有正确tcp时间戳的,不会被拒绝。
4.关闭内核参数net.ipv4.tcp_tw_recycle后恢复
- CVM内核调优 –
裸机常见内核优化参考
net.ipv4.ip_forward = 0 # 开启IP转发,根据业务需要开启
net.ipv4.conf.default.rp_filter = 1 # 开启反向路径过滤 1. 减少DDoS攻击 2. 防止IP Spoofing
net.ipv4.conf.default.accept_source_route = 0 # 处理无源路由的包
kernel.core_uses_pid = 1 #开启内核转存core dump,排错用
net.ipv4.tcp_syncookies = 1 #开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击
kernel.msgmnb = 65536 #消息队列的最大长度(bytes)。
kernel.msgmax = 65536 #进程之间发送消息的最大长度(bytes)
#优化网络传输
net.ipv4.conf.all.promote_secondaries = 1
net.ipv4.conf.default.promote_secondaries = 1
net.ipv6.neigh.default.gc_thresh3 = 4096
net.ipv4.neigh.default.gc_thresh3 = 4096
kernel.softlockup_panic = 1 #值为1可以让内核在死锁或者死循环的时候可以宕机重启
kernel.hung_task_panic=1 # 设置hung_task发生后是否引发panic
kernel.sysrq = 1 # 修改这个值为1激活SysRq来触发core dump,排错用
kernel.numa_balancing = 0 #NUMA平衡 默认关闭
kernel.shmmax = 68719476736 #配置共享内存段的最大值
kernel.printk = 5 #内核printk的打印级别
web常见内核优化参考
#打开syn cookie
net.ipv4.tcp_syncookies = 1
#降低接受/建立连接重试次数
net.ipv4.tcp_synack_retries = 3
net.ipv4.tcp_syn_retries = 3
#打开time wait端口复用
net.ipv4.tcp_tw_reuse = 1
#关闭tcp_tw_recycle/tcp_timestamps选项,避免HTTP代理导致的异常行为,net.ipv4.tcp_tw_recycle = 0
net.ipv4.tcp_timestamps = 0
#降低tcp time wait状态保持数量,快速释放资源
net.ipv4.tcp_max_tw_buckets = 5000
#降低tcp FIN_WAIT_2状态超时时间
lnet.ipv4.tcp_fin_timeout = 15